Why Enterprise AI Fails in Production: Security, Data & Governance Gaps
Quick answer:
Enterprise AI fails in production not because the model is wrong – but because of everything around it. The root causes are data pipeline failures (stale or unvalidated inputs), poor integration with legacy systems, shadow AI use by employees outside IT oversight, and a complete absence of auditability and monitoring. Under the EU AI Act and GDPR, these gaps also carry significant compliance risk for organizations operating in Switzerland, Germany, France, and beyond. Fixing AI failures in production requires governance-first architecture, not better models.
Most enterprise AI projects don’t fail because the model is wrong. They fail because of everything around it.
And yet, when an AI rollout goes sideways, most post-mortems still point to the model – the algorithm, the accuracy score, the benchmark result. That framing misses the real story entirely.
Across industries – from financial services firms in Frankfurt and Zurich to healthcare networks across the Netherlands and the UK – we’re watching the same pattern repeat itself. A proof-of-concept that wowed everyone in the demo environment quietly falls apart the moment it enters production. Real users. Real data. Real consequences.
And the root cause is almost never the model.
This article is not about explaining what AI is. It’s about where it actually breaks – and what it takes to fix it before the failure costs more than the project was worth.

1. Model Failure Is a Symptom, Not the Root Cause
Quick answer:
Enterprise AI fails in production because organizations treat the model as the product – when the model is actually the last piece of a much larger system. According to Gartner, through 2025, 85% of AI projects that fail do so not due to model performance, but due to data, process, and organizational issues. A recommendation engine serves wrong outputs because data hasn’t refreshed in weeks. A fraud model flags clean transactions because it was trained on a different market’s patterns. A generative assistant gives a customer incorrect information because no guardrails were set. In every case, the model did exactly what it was designed to do.
The failure happened upstream – in the data, the integration layer, or the governance process. Replacing the model changes nothing. Addressing the root causes does.
Consider three scenarios we see consistently across EU and US enterprise deployments:
- A recommendation engine serves irrelevant results because the underlying customer data hasn’t been updated in six weeks.
- A fraud detection model flags legitimate transactions because it was trained on data from a different regulatory environment.
- A generative AI assistant gives a customer incorrect information because no one set guardrails on what it could or couldn’t say.
In each scenario, the model did exactly what it was designed to do. Enterprise AI failed in production because the surrounding system wasn’t ready.
2. Data Pipeline Risks: What Happens When the Input Is Broken
Quick answer:
AI data pipeline failures are the single most common reason enterprise AI fails in production. Data pipelines in large organizations pull from multiple sources – legacy systems, third-party APIs, internal databases – each with different update frequencies, formats, and quality controls. When that foundation is unstable, no model can compensate. pipeline is not a detail but the foundation.
The specific risks break down into three categories:
Data Staleness
AI models make predictions based on patterns in data. If that data is two months old in a market that shifts weekly – financial pricing, inventory levels, customer sentiment – the model’s outputs will be systematically wrong, and no one will know why.
Unvalidated Inputs
Most production pipelines lack validation layers that check whether incoming data is within expected ranges, correctly formatted, or free from anomalies. A single corrupted record at ingestion can propagate errors across an entire inference pipeline.
Data Poisoning
This is the risk organizations rarely want to discuss. In adversarial environments – which includes most external-facing enterprise applications – bad actors can deliberately introduce malformed data to skew model behavior. Without monitoring at the input layer, this goes undetected until the damage is done.
Under the EU AI Act, high-risk AI systems must meet strict data governance requirements. For organizations operating across Switzerland, Germany, France, or anywhere in the EU, the compliance implications of a weak data pipeline go well beyond technical failure.

3. Integration Issues: When AI Meets Legacy Infrastructure
Quick answer:
Enterprise AI integration failures occur when AI systems are layered onto infrastructure that was designed for deterministic, structured workflows – not probabilistic machine learning outputs. The friction point is fundamental: legacy systems expect predictable inputs and outputs; AI introduces uncertainty, latency variability, and failure modes that traditional IT architecture was never built to handle. This gap is the second most common reason enterprise AI fails in production.
Common integration failure points include:
- API latency: When an AI model requires real-time inference but the surrounding systems cannot deliver data fast enough, the whole pipeline slows down or breaks entirely.
- Format mismatches: Legacy databases often output data in formats that modern AI tooling cannot natively consume, requiring transformation layers that introduce their own failure modes.
- Lack of fallback logic: What happens when the AI model is unavailable, times out, or returns a low-confidence result? Most integrations don’t have a clear answer.
- Single points of failure: When AI is embedded deeply into a business process without redundancy, any disruption in the model’s availability cascades into operational failure.
This problem is especially acute in organizations that move quickly from proof-of-concept to production. The PoC worked because it operated in isolation. Production is never isolated.
Swiss and EU enterprise clients we work with – particularly in banking and insurance – often face the additional complexity of needing AI systems to integrate with core banking platforms and comply with FINMA requirements simultaneously. That combination requires integration architecture designed from day one, not bolted on afterward.
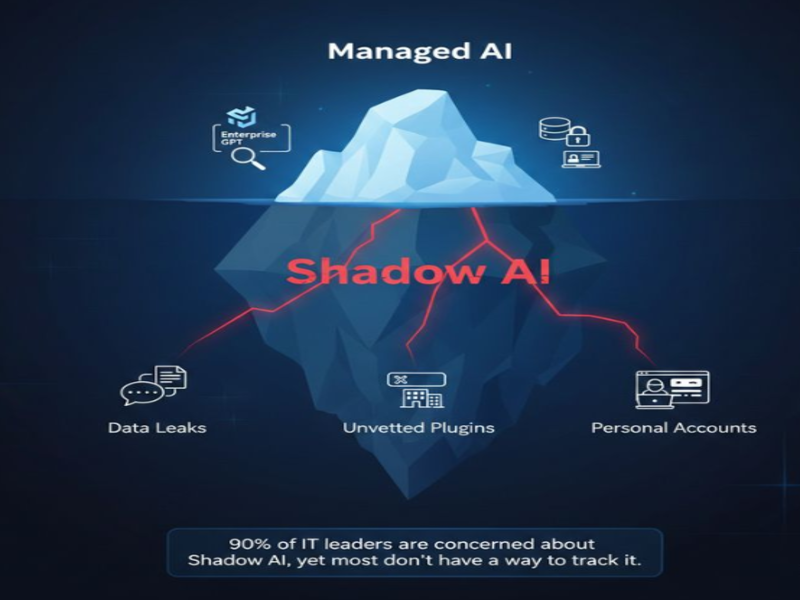
4. Shadow AI and GenAI Misuse: The Risk You’re Not Tracking
Quick answer:
Shadow AI refers to the use of AI tools – particularly consumer-grade generative AI platforms – by employees outside of IT oversight, without approved workflows, security review, or data controls. It is a leading cause of why enterprise AI fails in production, because the failure is invisible to leadership until a breach, a compliance incident, or a reputational event forces it into view. A 2024 study by Cyberhaven found that 11% of data pasted into tools like ChatGPT by employees is classified as confidential.
This is the one most leadership teams don’t want to hear about – because it is already happening inside their organizations.
A consultant in Zurich pastes a client’s financial summary into ChatGPT to draft a report. A developer in Amsterdam uses a public LLM to debug proprietary code. A sales team in Paris runs customer data through an unauthorized AI tool to generate proposals.
Each of these scenarios is happening right now in organizations that believe they have an AI governance policy.
The problem is not that employees want to use AI. They should. The problem is the absence of safe, sanctioned alternatives – which creates exactly the conditions where shadow AI thrives. And the consequences are serious:
- GDPR violations: Inputting personal data into a third-party AI platform with no data processing agreement in place is a clear breach of GDPR obligations, carrying fines of up to 4% of global annual revenue.
- Intellectual property exposure: Proprietary business information entered into consumer AI tools may be used for model training depending on the platform’s terms of service.
- Reputational risk: AI-generated content published externally without review – hallucinated facts, incorrect data, or inappropriate tone – creates brand and legal exposure that legal teams are only beginning to account for.
A 2024 study by Cyberhaven found that 11% of data employees paste into ChatGPT is classified as confidential. That number is almost certainly higher in enterprise environments with high volumes of sensitive client data.
The answer isn’t to ban AI tools. It’s to build internal, governed alternatives – and make them easier to use than the unauthorized ones.
5. The Auditability Gap: You Can’t Fix What You Can’t Trace
Quick answer:
Enterprise AI auditability refers to the ability to trace why a model produced a specific output at a specific moment and to demonstrate that process to regulators, customers, or internal reviewers. Without it, organizations cannot detect model drift, respond to complaints, or prove compliance. This is not an emerging requirement. The EU AI Act mandates detailed logging and human oversight for high-risk AI systems. For organizations in financial services, healthcare, or insurance across the EU, US, and Switzerland, the absence of auditability is already a compliance failure – not a future risk.
When a human makes a business decision that turns out to be wrong, there is usually a trail. A conversation. An email. A reasoning process that can be reconstructed and reviewed.
When an AI system makes a decision, that trail often doesn’t exist. This is the auditability problem – and it is one of the most underappreciated risks in enterprise AI deployment.
Without auditability, organizations cannot:
- Identify why a model produced a specific output in a specific case
- Detect model drift – the gradual degradation in model performance as real-world conditions shift away from the training distribution
- Demonstrate compliance to regulators who are increasingly demanding explainability for AI-assisted decisions in credit, insurance, healthcare, and hiring
- Respond effectively to customer or client complaints about AI-generated outcomes
Model drift is a particularly insidious issue. A model that performed well at deployment will naturally degrade as the world changes around it – market conditions shift, customer behavior evolves, regulatory requirements update. Without monitoring infrastructure in place, this degradation is invisible until it produces a visible failure.
Auditability is not just a compliance requirement. It is the feedback loop that makes AI systems improvable over time. For US and EU companies – and for Swiss financial institutions under FINMA’s increasing AI scrutiny – this is not a future alignment problem. It is a current operational and regulatory reality.
6. What Production-Ready Enterprise AI Actually Looks Like
Quick answer:
Production-ready enterprise AI is not defined by model sophistication. It is defined by the governance, data infrastructure, and monitoring architecture surrounding the model. Organizations that consistently deploy AI in production without failure share five characteristics: validated data pipelines with defined ownership, integration design that accounts for model unavailability, a governed GenAI policy with internal tooling, continuous monitoring and drift detection, and model selection criteria that include explainability alongside accuracy. These are not aspirational standards – they are the baseline for enterprise AI that works.
Clear data ownership and pipeline validation
Every data source feeding an AI system has a defined owner, an update frequency, and a validation layer that checks for staleness, anomalies, and format integrity before data reaches the model.
Integration design that accounts for failure
AI systems are designed with explicit fallback behaviors – what the system does when the model is unavailable, slow, or low-confidence. Redundancy is built in, not retrofitted.
A governed GenAI policy with internal tooling
Rather than banning AI tools and watching shadow AI proliferate, leading organizations deploy sanctioned, security-reviewed AI assistants with clear data handling policies and audit logs. Employees have a safe path to use AI – and no reason to go around it.
Monitoring and drift detection from day one
Production AI systems are treated like live software: monitored continuously, with alerting for performance degradation, and scheduled retraining cycles tied to data refresh rates.
Explainability built into the model selection process
For regulated use cases – credit decisions, insurance underwriting, medical triage – model selection explicitly accounts for interpretability requirements, not just accuracy benchmarks.
These are not aspirational standards. They are the baseline for organizations serious about AI in production. Explore the blog for more on enterprise AI architecture, or contact our team to discuss your specific environment.

7. FAQ: Why Enterprise AI Fails in Production
Why does enterprise AI fail in production if the model performs well in testing?
Enterprise AI fails in production when a model that performs well in a controlled test environment encounters the complexity of real operational infrastructure. The most common reasons are data pipeline failures (stale, unvalidated, or corrupted inputs), integration breakdowns with legacy systems that were not designed for probabilistic AI outputs, and the absence of monitoring to detect when model performance degrades over time. Testing environments rarely replicate the noise, inconsistency, and edge cases of live data. A model’s benchmark accuracy does not predict its production behavior – the surrounding system determines that.
What is shadow AI and why is it a risk for enterprise organizations?
Shadow AI refers to the use of AI tools – especially consumer generative AI platforms like ChatGPT – by employees without IT approval, security review, or data governance controls. It is a risk because employees routinely input confidential business data, client information, or proprietary code into these platforms, creating GDPR exposure, intellectual property risk, and potential regulatory violations. A 2024 Cyberhaven study found 11% of employee-pasted content in consumer AI tools is classified as confidential. Shadow AI thrives when organizations ban AI tools without providing a safe, governed alternative.
What does AI auditability mean in an enterprise context?
AI auditability in an enterprise context is the ability to trace and explain why an AI system produced a specific output at a specific moment – and to demonstrate that process to regulators, auditors, or customers. It includes maintaining logs of model inputs and outputs, monitoring for performance drift, and ensuring that AI-assisted decisions in regulated domains (credit, insurance, healthcare) can be explained and reviewed by humans. Under the EU AI Act, auditability is a legal requirement for high-risk AI systems. Without it, organizations cannot detect failures, respond to complaints, or demonstrate compliance.
What is the most important first step to prevent enterprise AI from failing in production?
The most important first step to prevent enterprise AI from failing in production is a data infrastructure audit – not a model evaluation. Before selecting or deploying any AI system, organizations should map every data source feeding the model, define ownership and update frequency for each, and implement validation layers that check data quality at ingestion. Most AI production failures trace back to the quality, freshness, or integrity of input data. Fixing the data foundation before deployment is faster and less costly than diagnosing failures after go-live – and it is the prerequisite for everything else in enterprise AI governance.
8. Conclusion
Enterprise AI fails in production for reasons that have almost nothing to do with the model. Data pipelines that are stale or unvalidated. Legacy infrastructure that was never designed for probabilistic outputs. Employees using unauthorized AI tools outside any governance framework. And a complete absence of the monitoring and auditability needed to detect when things are going wrong.
The organizations winning with AI are not the ones with the most sophisticated models. They are the ones that took data governance, integration design, security, and auditability seriously before they went to production.
With extensive experience advising and delivering solutions across multiple industries, IMT partners with organizations to evaluate IT maturity, define pragmatic modernization roadmaps, and design AI architectures aligned with long-term business strategy. Rather than implementing fragmented initiatives, IMT focuses on building sustainable technology capabilities that enable enterprises to adapt to AI-driven change with confidence. By establishing resilient, scalable foundations, IMT helps organizations unlock AI value responsibly and support sustainable enterprise growth. Contact IMT to begin your IT modernization journey today.







